
What is Apache Spark?
What is Apache Spark?
Apache Spark is an open-source cluster computing framework for running real-time processing of large-scale data analytics. This technology was designed in 2009 primarily to support and speed up processing jobs in Hadoop systems.
Since its inception to the latest version 2.0 released in 2016, Spark has evolved as a market giant in Big Data processing. Many global IT and software giants are adopting this technology for their current and upcoming projects.
Apache Spark is a cluster computational framework, which is designed to be faster. This is currently licensed under Apache software foundation. This has become the fastest computational engine that can process data up to the size of petabytes.
For working upon very huge datasets, Hadoop was primarily used before. Hadoop uses Map Reduce method to work upon data. This MapReduce used two techniques: Map – In this technique, the large sets of data are mapped into a function and produce another set of data. Reduce – In this technique, the output of Map technique is taken and worked upon, to give fewer sets of data.
For example, if we have a series of natural numbers, which needs the sum of all squared numbers. Using the (Map) first method, we take each number and square it. In this technique, if we need n data, the output size will also be n. In the reduce method, we take the output of the first technique and perform the sum of all squared numbers. In the second method, the size of output is clearly one.
Hadoop uses this programming model to process very huge data sets. Spark is introduced to give better speed than Hadoop, which is likely to be 100 times more.
Features of Apache Spark:
Lightning speed:
Apache Spark is said to have a speed that is 100 times better than Hadoop. This currently holds a world record for speed processing for data that is stored on disk.
Easy Integration:
It supports a lot of languages. Spark has inbuilt APIs to support languages like Java, Scala, Python and much more. You don’t really need to learn a new language just to work with Spark. If you can do programming in one of the languages being supported by Spark, you can use Spark without any hassle.
How Spark Works:
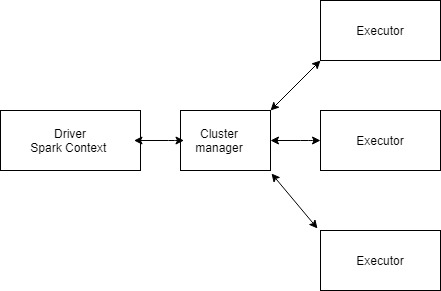 The architecture of Spark is built upon Resilient Distributed Datasets (RDD). These data sets are distributed over a cluster of machines. These data can rebuild themselves if any failure occurs in any of the clusters and this is why they are called resilient.
The architecture of Spark is built upon Resilient Distributed Datasets (RDD). These data sets are distributed over a cluster of machines. These data can rebuild themselves if any failure occurs in any of the clusters and this is why they are called resilient.
Spark is based on master/slave architecture. In this type of architecture, there is only one central master who commands a number of slaves. Here, the master/ central coordinator is called the driver. The slaves/ other workers which are distributed are called the executors. Each of this driver or executor runs its own java process. Hence, to support this type of architecture, Spark needs a cluster manager for its driver and a distributed storage system for all its executors. Spark has it’s own built-in cluster manager or it can support Hadoop YARN or Apache Mesos. In order to support its distributed system, it supports a lot of storage systems. Among them are Cassandra, HDFS, Amazon S3, etc.
Advance Engine:

- Spark SQL has introduced Data Frames. Data frame is nothing but a 2 d array structures which arranges data in rows and columns. Data frame supports both structured and semi-structured data.
- Spark Streaming is another feature that performs both batch and stream processing. It is capable of processing data that is streaming in real time. Its ease of use and fault tolerance make it popular. It easily integrates with other data sources such as Hive, HDFS, Kafka, etc.
- MLib is the machine learning library which has high-quality algorithms. This is faster and runs everywhere. Hence, this makes it a great tool for machine learning programmers for its speed and ease of use.
- GraphX has the competing algorithms that are focused on analyzing the graph-structured data at large scale.
Applications of Apache Spark:
Due to its speed and versatility, Spark is widely used in a lot of fields such as Entertainment, E-commerce, Finance and so on.
Netflix, Uber, Pinterest are a few of the companies that use Spark.
The Spark Advantage
You must be wondering what makes Spark more expedient compared to Hadoop. The main difference lies in the functioning and processing methodology of both the tools. Spark owns the following key features: speed, multi lingual support and advanced analytics functionality.
Speed
For a better understanding of performance speed of Spark, a comparison with MapReduce gives a clear figure. When processed in-memory, Spark is a hundred times faster than MapReduce and when done on disk, it is ten times faster than the latter. This is achievable because of reduced number of read/write operations to disk and storage of the intermediate processing data in memory.
Multi-Lingual Support
Spark is amazing when it comes to providing functionality to code in various languages. With Spark, you can code in Java, Scala or Python; thus designing applications in various languages is very convenient using Spark. Spark also provides 80 high-level operators for interactive querying.
Though Scala is considered the primary language for interacting with the Spark Core engine, Spark also comes with
API connectors for using Java and Python. Users can also download R programming package and run in Spark. This explains the unique leverage Spark offers to build machine learning algorithms in multi languages.
There is also an R programming package that users can download and run in Spark. This enables users to run the popular desktop data science language on larger distributed data sets in Spark and to use it to build applications that leverage machine learning algorithms.
Advanced Analytics
Besides supporting Map Reduce, Spark also offers works with SQL queries, Streaming data, Machine learning (ML), and Graph algorithms.
The advanced functionalities performed by Spark can be attributed to Spark Core. Designed with Resilient Distributed Data (RDD) as its basic data type, Spark Core provisions many key functionalities of Spark:
- Gathers and divides data across the server cluster for further processing
- Hides complex computations from users
- Retrieves files and data from their locations, without any need of explicit definition from users.
Besides, Spark also offers many advanced features compared to Hadoop:
- Performs much more than just batch processing applications, compared to MapReduce
- Handles data from multiple repositories and relational databases
- Enhances the performance of big data analytics based applications through in-memory processing
- Supports and performs conventional disk based processing to fit huge data sets
A point to note here is that Spark uses Hadoop for two purposes: storage and processing. Hadoop comes into picture mainly for storage purpose, as Spark has its own cluster management computation.
Spark Libraries
Spark is rich in libraries that offer many useful functionalities. Spark SQL, Spark Streaming, MLlib, GraphX, etc. are some of the key libraries that enable a user to design top level code using Spark.
Apache Spark Use Cases
The rich features and wide range of libraries available in Spark lets the users to apply it in many real time applications as follows:
Medical Care:
Maintaining Electronic Health Records (EHRs), predicting patient’s health issues, strategic planning through patient health data, etc.
Communication:
Network Optimization and Predictive Analysis, Customer retention planning and strategies, identifying revenue leakages, etc.
Banking:
Fraud detection, Retention of customer base, Risk management, Offering better customized services and products to customers
Share Markets:
Daily investment forecasts, Choosing and making trading strategies.
Government:
Prediction polling, tackling fraud and waste, legislation making, etc.
Now that we have seen how Spark gains advantage over Hadoop and its unique features that enables its application in many real time case studies, you are all confident to start your journey with Spark and master it.\

 +1 201-949-7520
+1 201-949-7520 +91-9707 240 250
+91-9707 240 250