
What is Machine Learning?
Table of Contents
1. What is Machine Learning?
Machine Learning: As the name says, the machine learns something from the examples and experiences without being explicitly programming. There is already a pre-written generic algorithm, so instead of writing codes, we just pass the data to the generic algorithm. The algorithm builds its logic based on the data that is been passed to it. “Machine learning is a field of computer science that gives computers the ability to learn without being explicitly programmed.”
Examples:
Let us see some real-life examples that we have come across in our day-to-day life.
Ever wondered how Amazon suggests other products related to your purchase or how Google shows other related searches at the bottom of the page. Simple, they use Machine Learning algorithms to map your search and show you related searches you are watching a series posted on YouTube in your favorite channel, you start with Episode-1; there are chances that you are likely to get the Episode-2 in your recommended list of next video.
Machine Learning Tutorial For Beginners | GangBoard
1.1 Machine Learning Tasks
Machine learning enables computers to make data-driven decisions, without being explicitly programmed to carry out certain tasks. All the machine learning algorithms are designed in such a way that it learns from the data passed to it and improve themselves over time when they are passed with new data
1.2 How It Works
There are two main phases of the algorithm:
- Train Data
- Test Data
The data is divided into train data and test data. Depending on the person, the train data and test data size vary. It is a good practice to maintain the train data percentage greater than the test data percentage.
For example,
- Train Data – 80%
- Test Data – 20%
Bypassing the train data to the model, the machine learns from the passed data and when test data or new data is been passed to it, it starts predicting based on what it has already learned from the training data.
2. History Of Machine Learning
We are aware that we live in a world of humans and machines. Humans learn from their experiences and evolve for many years. Now, it is the era of machines and robots. Machines have started to learn and evolve; we call it as Machine learning. We can say Machine Learning is the subset of Artificial Intelligence.
Machine Learning uses algorithms to improve their performance. There is already a pre-written generic algorithm, so instead of writing codes, we just pass the data to the generic algorithm. The algorithm builds its logic based on the data that is been passed to it. It automatically builds a model using the train data, which is also known as sample data. Once it has learned from the training data and when new data is been passed to it, it starts predicting what it has learned from the training data.
In 1950, Alan Turing, to determine if the computer has real intelligence, created the Turing Test. In order to pass the test, the computer must fool a human into believing that it is a human.
In 1952, Arthur Samuel wrote the first computer learning program. It was a game checker program. The computer improved with the more games it played, it incorporated those moves and made up winning strategies.
In 2016 – Google created an artificial algorithm, which beats a player at a Chinese board game, Go. This game is been considered as a most complex board game and it is many times harder than chess
Machine Learning: When do we use it?
A simple problem can always be solved by designing simple code in any particular Language like Python, R, etc. But in case of very complex problems, Machine Learning comes into the picture. We can also use it when the problem involves a huge amount of data where there isn’t any formula or equation existing to solve.
For Example:
- Face recognition
- Speech recognition.
- Fraud detection
- Demand forecasting
2.1 Relation To Data Mining
Data Mining refers to extracting information from data. It is been used to discover various patterns that are in the data, which will be of some use. It is been used to predict future outcomes. Machine learning models are been built using data mining techniques that power artificial intelligence applications like recommendation systems, search engine algorithms.
Data Mining involves the following steps,
- Good understanding of business
- Understanding of data
- Data preparation
- Modeling of data
- Evaluation
- Deployment
2.1.1 Benefits Of Data Mining
- Accurate prediction and forecasting
- Automated decision making
- Cost reduction
2.2 Relation To Optimization
Optimization is considered as the heart of machine learning techniques used in data science. There are many optimization algorithms used in machine learning. We will now see one optimization algorithm.
Stochastic Gradient Descent
It is one of the simplest optimization algorithm used to find the best suitable parameters to minimize the cost function. Initially, we define random values to parameters. Here the goal is to find the parameter value that gives the minimum value of cost function.
2.3 Relation To Statistics
Machine learning is a recent deployment, whereas, statistics have been there for centuries. Machine learning came to existence in the 1990s. Machine learning models have various statistical assumptions.
For example, let us consider linear regression, it has the following assumptions,
- A linear relationship between the independent variable and the dependent variable
- Little or no multicollinearity between the features(independent variables)
- Homoscedasticity
- Normal distribution of error terms
- Little or no autocorrelation
3. Introduction To Data In Machine Learning
The most important part of data analytics, data science, machine learning, deep learning, artificial intelligence is data. Without proper data, we cannot train models. Many big enterprises are spending money just on gathering as much data as possible.
The data that is received will not always be in a structured format, mostly it will be in an unstructured format. The data may contain missing values, outliers, string variables and it may require some pre-processing works. Data with missing values and string variables, when passed to model, will throw an error. Data with outliers, when passed to model, affect the performance of the model. All these need to be taken care of before passing our data to the model.
3.1 Steps In Data Processing
- Collecting data
- Analysis of data
- Exploring and transforming data
- Data modeling and evaluation
Collecting data
First step involves in data collection for building the machine-learning model
Analysis of data
In this step, initial understanding of variables in the data, data type of each variable, missing value check, outlier treatment and collecting statistical information for better understanding is been carried out Exploring and transforming data: In this step, insignificant variables are been dropped; creation of new variables based on the requirement, dealing with missing values, outlier’s string variables is carried out
Data modeling and evaluation
After the data is been transformed as per requirements, it can be passed into a model for prediction. Once the predictions are completed, it is necessary to check the performance of the model. The performance check is been done by calculating the evaluation metrics, which gives the accuracy percent of the model prediction
Read This blog: Machine Learning using Python
4. Machine Learning Algorithm Types
There are many algorithms available in machine learning. As a practitioner, one may encounter many types of algorithms. In this, we will discuss the types of machine learning algorithms.
4.1 Types of Machine Learning Algorithms
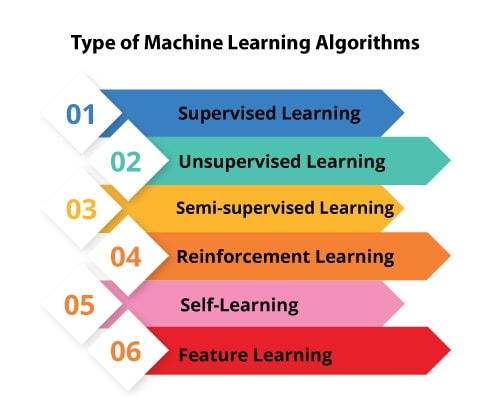
4.2 Supervised Learning
Supervised Learning is a type of Machine Learning used to learn models with labeled training data. Supervised machine learning algorithm involves using a model, the model learns from input examples and the target variables. The majority of practical industrial problems revolve supervised machine learning.
In supervised machine learning, we will be provided with a data set in which we will have input variables (Independent variables) and an output variable (dependent variable). We use an algorithm to map the function from the input variable to the output variable.
There two types of supervised machine learning:
- Regression
- Classification
Regression
In regression models target (dependent variable) prediction value is based on features (independent variable). Regression is been used for finding the relationship between an independent variable and a dependent variable. For example, Consider, we need to predict the crop yield based on rainfall. In this case,
- Crop yield will be the dependent variable
- Rainfall will be the independent variable
Crop yield is dependent on rainfall. Therefore, crop yield is a dependent variable. Whereas, rainfall is not dependent on crop yield, so, it is an independent variable. A data set can have any number of independent variables but there can be only one dependent variable and it has to continuous.
Classification
Classification is nothing but separating/classifying our data into different categories. The categories can be binominal or multinomial. Like,
- Gender – Male, Female
- True or False
- Yes or No
For example,
Given a data set of weather, making predictions whether it will rain or not i.e. classifying into two discrete categories. Logistic Regression is one best example of classification problems.
When do we use Supervised Leaning?
We opt Supervised Learning technique when we know what we want the algorithm/model to do which means we know exactly what the Target element here is. Few examples that both model and us know the answer to are used to train the model which in turn helps in predicting other examples where we/model doesn’t know answers to.
For Example:
- Face recognition,
- Diagnosis,
- Email spam detector etc.

4.2.1 Some Common Algorithms
- Linear Regression
- Support Vector Machine(SVM)
- Decision Tree
- Neural Networks
- K Nearest Neighbour
4.3 Unsupervised Machine Learning Algorithms
Unsupervised Learning is a type of Machine Learning that always feeds on the unlabeled dataset.In unsupervised machine learning algorithms, we have input data and there will be no corresponding input variables. The main goal of unsupervised machine learning algorithms is to model the underlying structure in the data in order to learn more about what the data is. We will approach the data/problems with little or no idea about what our results may look like. This is been done by clustering the data, our model cluster/group the data based on the relationship among the variables in the data.
4.3.1 Some Common Algorithms
- K Means Clustering
- Hierarchical Clustering
- Association Rules
Clustering
Clustering algorithms group the data based on objects that fall under the same group (cluster) or more similar to each other than those in other groups. The model has its own logic in grouping by considering all the hidden logic in the data set.
For example, We have a collection of 1, 00,000,000 different genes, we need to automatically group/cluster the genes into groups based on their similarities such as lifespan, role and so on.
When do we use Unsupervised Learning?
Generally, we opt Unsupervised Learning technique when we don’t know what exactly we want the algorithm to do. In this case, we have to be discovering patterns from the unlabeled data inputted and predict the results informatively. For Example GoogleNews search (Clusters) etc.
Types of Unsupervised Learning:
- Clustering
- Anomaly Detection
- Recommendation System

Recommendation System:

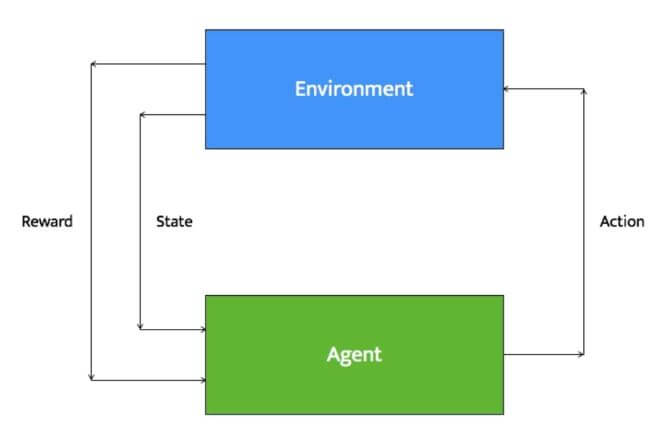
4.4 Reinforcement Learning
The learning of reinforcement learning is different from supervised machine learning and unsupervised machine learning. Reinforcement learning is all learning from mistakes. Reinforcement learning makes many mistakes in the beginning, as long as we provide some data to our model, it learns from the data and makes fewer mistakes than it used to.
4.4.1 Some Common Algorithms
- Temporal Difference
- Q-Learning
- Deep Adversarial Network
The reinforcement learning system is mainly known for multitasking. It’s also called a Trial and Error technique as it uses trial and error methods in learning the model. Once the model is been learned, it’s used in predicting the next steps in upcoming iterations.The model will return a state and the User/Agent will decide to Reward or Punish the model based on the output generation.
- Reward – Positive Feedback
- Punish – Negative Feedback
Reinforcement Learning is also known as Feedback based learning.
4.5 Feature Learning
Feature learning is a set of techniques in machine learning that allows in detecting the features that are needed for feature detection or classification. Manual feature engineering is replaced by this. Thus, allowing machines to learn the features and to use them to perform some specific tasks.
Most of the classification algorithms in machine learning require data inputs to be in a computationally convenient way to process. However, the data received in real life can be expected to be in structure format, most of the time it will be in an unstructured format.
- In supervised machine learning, the features are learned by labeled input data.
- In unsupervised machine learning, the features are learned with unlabelled input data
4.6 Sparse Dictionary Learning
Sparse Dictionary Learning is a branch of signal processing and machine learning that aims in finding a frame (dictionary) in which the training data is present in a sparse representation. It is a representation-learning method; it aims to find a sparse representation of the input data.
4.7 Anomaly Detection
One way of processing our data faster and in a more efficient way is by detecting the abnormal events in the datasets. Anomaly detection is nothing but identifying events or items that are not in expected patterns or items in datasets that are undetectable by humans.
4.7.1 Examples Of Anomalies
- A production system being shut down by a leaking connection
- Bank fraudulent transaction
- Failed login for multiple login attempt indication cyber threat activities
4.8 Association rules
Many of you might have come across association rule or association learning many times in your life without knowing it is association rule. It is one of the very important concepts of machine learning which is widely used in market analysis. In a supermarket, every item is arranged in an orderly manner, all cosmetics be placed separately, all dairy products placed separately, all vegetable placed separately, etc., this helps customer not only in reducing the time of shopping but also helps them to choose relevant items or products in which they might be interested.
Examples
- Netflix showing relevant videos to you, when you search for a particular genre
- Amazon suggesting relevant products for purchase
- Google showing related searches when you search for something
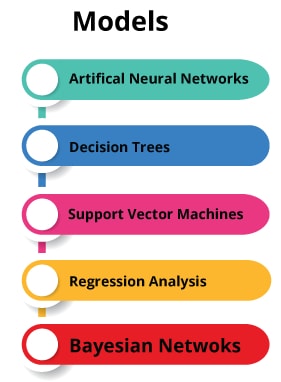
5. Models in Machine Learning
6. Applications Of Machine Learning
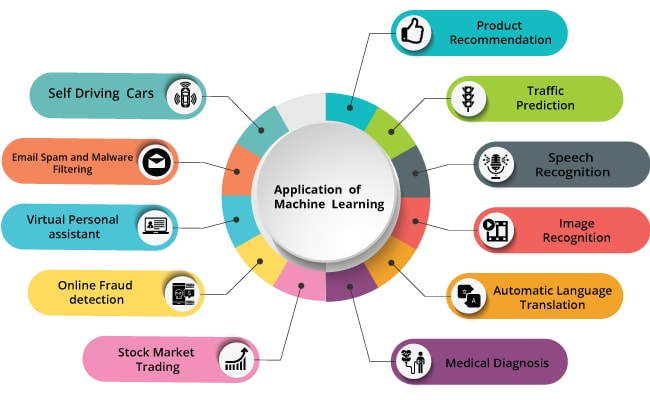
We move towards the digital age, we have seen rapidly advanced technologies. Machine learning a subset of artificial intelligence is used in various industries to make predictions such as profit estimation, sales prediction, weather forecasting, grouping data to find hidden patterns and logics, reduction in cost, speech recognition, text classification, medical diagnosis, etc. there are many real-life applications of machine learning. Let us see them,
Personal Assistants:
Alexa, Google Mini, Siri are some of the popular virtual personal assistance. They assist in finding information when asked. First, you need to activate them and ask any questions or even you can instruct them to remind you a particular time i.e. like an alarm
Video Surveillance:
Monitoring multiple video cameras by a single person is difficult. Nowadays, video surveillance is powered by artificial intelligence which makes it possible to detect crime before even they happen
Face Recognition:
You might have noticed, if you upload an image of you with your friend, Facebook recognizes your friend instantly. Facebook checks the projections in the picture, poses, unique features and matches them with the people in your friend’s list
Email Spam Filtering:
You may have noticed, few of your emails going into spam. These are rule-based spam filtering; they are powered by machine learning
Search Engine Results:
Search Engines like Google use machine learning to improve search results. Every time you search, there will be algorithms at the backend, to track your search and respond to the results
Product Recommendation:
Amazon is one best example of this application. Shopping websites like Amazon recommends you with products related to your search
Online Customer Support:
We can consider chatbots as online customer support. You may have noticed many websites having chatbots to assist you once you enter their site. These chatbots extract information from the website and present it to the customer
Online Production Detection:
Many online payment sites uses machine learning to protect against money laundering. There will be millions of transaction happening every minute, these algorithms distinguish between legitimate or illegitimate transactions
Marketing and Sales:
Machine learnings algorithms analyze the purchase history of every customer and recommend products in order to make customers buy it again
Healthcare:
Machine-learning algorithms play an important role in the healthcare industry. Sensors that are fixed to the wearables of a patient provide information on patient condition, blood pressure, heartbeat, etc.
7. Limitations Of Machine Learning
Be it any field, there will be certain limitations to it. Likewise, we have limitations to machine learning also. In this, we are going to discuss where machine learning is the right solution and where it is not the right solution. Machine learning is not a solution to all the problems; there are times when machine learning fails to provide us with a solution. The collection of large amounts of data is now possible which has paved the way for us to analyze the data and infer what about the data. It helps in gaining insights into the data.
It is no wonder why machine learning has so much impact on the world, what we are less clear is what are the limitations or capabilities of machine learning. There is a term called ‘dataism’, Yuval Noah Harari coined it, it says that, ‘we are then trusting our own judgment and logic’ entering into a new stage of civilization, where we trust algorithms more No wonder, we trust GPS blindly when we go on a trip to a new.
7.1 Massive Training Data
Machine learning models are been trained not programmed. Therefore, it requires enormous data on which it will be trained. Once it is been trained on the data that is passed to the model, it starts predicting the new data we pass to it. But, the model requires a large number of training data for it to predict test data. If the model is not trained on the required amount of training data, the prediction of the model will be affected.
7.2 Bias
If you are already aware of machine learning then you could relate how creepy bias could be. It is not that bias is strictly an ethics-related issue. It is actually a performance issue affecting the effectiveness of the system. There is a wide range of bias but the best place, to begin with, is two-level concepts.
- Technical and contextual bias
- Pre-existing and data bias
Technical and contextual bias
It is all about how the algorithm is been programmed. In machine-learning we need not write our own code to perform some modeling, there is a generic code pre-written, which needs to be called and data needs to be passed to it.
It refers to problems that arise to be operated in a specific way.
Pre_existing and data bias
This bias is embedded in the train data that we choose to pass to our algorithm for training purposes. However, every data will somehow be biased in some way like the data might having missing values, outliers, etc.,
8. Model assessments
There are many machine learning algorithms available. Not every dataset can be passed into every machine-learning algorithm. There are certain criteria that need to be met by the dataset for it to be passed to certain models.
Linear Regression
- One dependent variable, one or many independent variables
- Dependent variable should be continuous
- For example Salary, Profit of a company
Logistic Regression
- One dependent variable, one or many independent variables
- Dependent variable should be binary(categorical)
- For example: Yes or No, True or False, 1 or 0
Once the right model is selected the data cannot be passed directly into the model, the data needs to pre-processed like data cleaning like missing value treatment, outlier treatment, etc., transforming data into required formation, performing exploratory data analysis, then passing the data into the chosen model.
Upon passing the data to the model, we have to calculate how accurately our model has performed. This can de be done using evaluation metrics. Evaluation metrics tell us the performance of the model. Evaluation metrics differ from model to model
Linear Regression
- r2_score
- MAPE – Mean Absolute Percentage Error
- MAE – Mean Absolute Error
- MSE – Mean Squared Error
Logistic Regression
- Confusion Matrix
- ROC curve
- F1 score
- Classification accuracy
- Precision and Recall
9. Ethics
Bias is the first step, which needs to be taken care of while thinking about ethics in machine learning. If you are already aware of machine learning then you could relate how creepy bias could be. It is not that bias is strictly an ethics-related issue. It is actually a performance issue affecting the effectiveness of the system. There is a wide range of bias but the best place, to begin with, is two-level concepts.
- Technical and contextual bias
- Pre-existing and data bias
Technical and contextual bias
It is all about how the algorithm is been programmed. In machine-learning we need not write our own code to perform some modeling, there is a generic code pre-written, which needs to be called and data needs to be passed to it. It refers to problems that arise to be operated in a specific way.
Pre_existing and data bias
This bias is embedded in the train data that we choose to pass to our algorithm for training purposes. However, every data will somehow be biased in some way like the data might having missing values, outliers, etc.,
10. The software’s Used In Machine Learning
There s no doubt that machine learning has emerged to be the most important technology of this century. There are so many algorithms available in machine learning, which can be used for performing various. In this session, we will cover the various software that is available, in which we can perform our python programming and machine learning algorithms. Though there are many software’s available, people usually use the software in which they are comfortable with. To write our codes, we require an IDE – Integrated Development Environment. The IDE can be anything; the code remains the same. Some IDE’s like Jupyter Notebook, Eclipse, Spider are widely used, as they are user-friendly. Also, there are many tools available in python for machine learning.
10.1 Software’s used
Scikit-Learn

It is one of the free software machine learning libraries available for Python. It is a simple, easy and efficient tool for machine learning which helps in data mining, data analysis, data visualization, etc., It is built on Numpy, Scipy, and Matplotlib. It has a wide range of supervised and unsupervised learning algorithms in python such as Regression, Classification, clustering, Association, Dimensionality Reduction.
Tensor Flow

It is an open-source library and offers the JS library, which helps in machine learning development. The APIs available will help us in creating and training models.
It is an open-source and people who have worked related to machine learning will be aware of this. It was developed by Google.
Pytorch

It is a python based library; it provides flexibility for the deep learning development platform. Its working is similar to a scientific computing library like Numpy. Facebook actively uses Pytorch for its Deep Learning and Machine Learning works
WEKA

WEKA stands for Waikato Environment for Knowledge Analysis. It is an open-source Java Software. It has many collections of machine learning algorithms that help in data mining, data analysis, data visualization, etc., One of the most powerful tools for visualization and understanding is WEKA.
WEKA has both a graphical interface and a command-line interface. One disadvantage is, it does not have much documentation and online support.
RapidMiner

It is a machine-learning platform. It has a powerful GUI(Graphical User Interface). It helps users in performing predictive analysis
11. Machine Learning And Artificial intelligence
Artificial intelligence and machine learning are two buzzwords and often seem to be used interchangeably. Both machine learning and artificial intelligence have become a part of our life. However, they are not the same thing. AI and ML have already made so much progress in the technological field. Machine learning is a part of artificial intelligence. AI and Ml have become more popular these days because of the increase in data size. Based on the available data we can predict, forecast, classify and gain more insights about the data. Be it artificial intelligence or machine learning, the goal will be to learn something from the data on certain tasks, which will maximize the performance of the machine on that particular task.
Artificial Intelligence
Artificial intelligence is nothing but the intelligence created by humans. It performs various actions just like humans. They have senses similar to humans. It is considered as the future of humanity and likely to make the lives of humans better. They are preferred as the best solution for tasks, which cannot be performed, by us or time-consuming tasks. A computer-operated machine can function similar to humans.
From the above discussion, it is clear that the ability of machines to think and work like the human brain is called artificial intelligence. Artificial intelligence work, think and react similarly to humans. Many think that artificial intelligence is a system, it is not, artificial intelligence is implemented in a system.
Machine Learning
Machine learning and deep learning are subsets of artificial intelligence. Machine learning and deep learnings are base or foundation to accomplish artificial intelligence. All ML and DL are counted as AI but not all AI are counted as Ml or DL.
Machine learning can modify itself when exposed to new data, once ML models are trained onset of data when new data is passed it can predict the new data. This makes ML less reliant and brittle on humans. Machine learning helps computers to learn something without explicitly programming it.

 +1 201-949-7520
+1 201-949-7520 +91-9707 240 250
+91-9707 240 250